ChatGPT set historical records for its unprecedented adoption rate, attracting one million users in five days and 100 million users in two months. For context, it took Instagram two and a half years to get to 100 million, and TikTok nine months. The exponential rise of AI tools is an exciting opportunity for businesses, but brings a whole host of new challenges. According to a survey of 12,000 workers in January 2023, 43% had already used tools like ChatGPT for work-related tasks – 70% of them without telling their boss. So, how do corporations and public administration mitigate the risks of integrating a new breed of AI tools in their environments, without missing the opportunities they bring?
The problem begins with the jungle of acronyms that characterizes the AI landscape today and the difficulty for laymen to understand the differences between the different concepts.

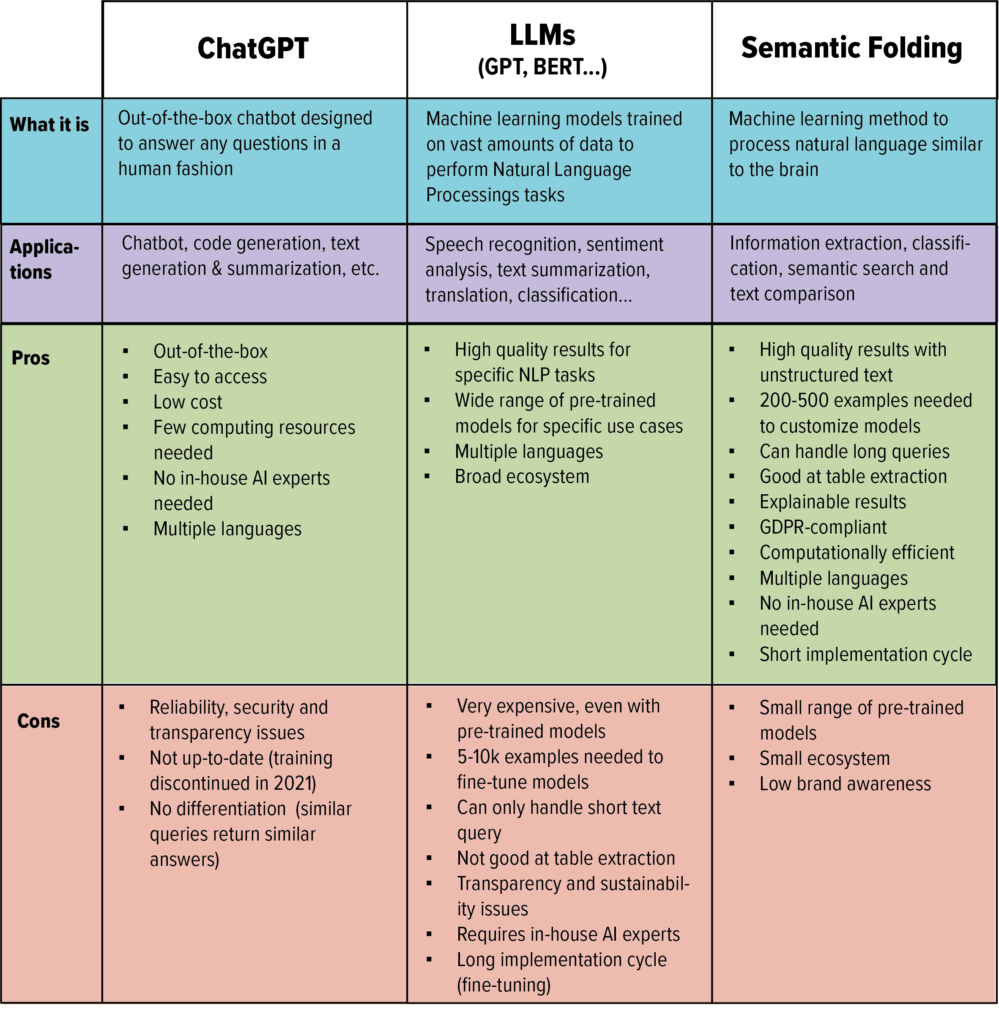
Welcome to the AI jungle: ChatGPT, LLM, BERT, Llama and the likes
A common area of confusion is between ChatGPT (the AI tool everyone’s talking about) and GPT (the large language model, or LLM, behind ChatGPT). While they might sound similar, it is fundamental to understand they are not the same.
ChatGPT is a kind of super chatbot that can generate answers in natural language (=like a human) on almost any topic, based on a few sentences as input (=prompt). It has been trained with a Large Language Model (LLM) called GPT (Generative Pre-trained Transformer) – the largest language model ever, developed by OpenAI (backed by Microsoft) with 175 billion parameters.
The extreme popularity of ChatGPT can be explained by its accessibility and the wide variety of use cases it serves. From drug discovery to material manufacturing, ChatGPT has the potential to revolutionize many industries.
But what does ChatGPT actually do? It can provide input for marketing copies, draft emails, summarize text, or even suggest lines of code to classify content. The more precise your prompt, the better the output, hence the emergence of a new discipline called prompt engineering. Alternatives to ChatGPT include other generative AI tools like Google Bard and Microsoft Bing Chat, as well as AI-based writing tools such as Jasper.
LLMs such as GPT and Google’s BERT are parts of what is called general purpose AI. These large models can be used to perform text-based tasks like translation, sentiment analysis and question answering. LLMs are trained on massive amounts of text data and can be integrated into generic AI tools like ChatGPT or in custom enterprise AI solutions for which they generally require to be fine-tuned by a team of data scientists. Some of them are open source (Meta’s LLama), whereas others, like GPT, must be licensed.
Now, apart from the type of applications they can help with, using ChatGPT or a large language model has significantly different implications for an enterprise-grade implementation. Let’s compare the most critical factors : access, costs, reliability, transparency, privacy and sustainability.
Ease of access and costs
The big difference between ChatGPT and large language models is the way they can be accessed and, consequently, their costs. While ChatGPT is an out-of-the-box tool that just asks you to create an account to get direct access, LLMs require significant in-house resources, including AI experts and data infrastructure to be deployed.
While ChatGPT only requires minimal upfront investment (basically, the costs of your development team to develop an application), the limited differentiation and control over its answers won’t be sufficient for many organizations’ needs, unless you’re building a very generic chatbot and are satisfied with rather superficial answers.
Hundreds of articles have already been written about the cost of training LLMs – researchers estimate that the costs of training GPT-3 amounted to $4.6 million. Fortunately, companies can leverage pre-trained versions of LLMs, which nevertheless require fine-tuning to match specific use cases. This customization process still requires substantial resources in terms of GPUs, cloud computing, and expertise, as we highlighted in a previous post.
 Reliability
Reliability
 Reliability
Reliability“Hallucination” is a phenomenon encountered with both ChatGPT and LLMs, which occasionally provide plausible, but totally wrong information, making it critical to add human quality controls before using the results. The more complicated the query, the higher the probability that the system delivers different answers to exactly the same request. This might not cause any problem for a marketing brief, but it is not acceptable in many business contexts – no legal or financial teams can work with approximations or sources they can’t absolutely trust.
The side effect of this is the ease with which these tools can be misused to create fake news and false content – from Ukraine having launched a new offensive or Donald Trump dressed up in orange drag asserting “Let’s make America glam” again.
Transparency
LLMs and, consequently, all tools using them—like ChatGPT—are black boxes. This means that there is no way to trace back why and how they delivered a certain output. This makes it very difficult to fix biases in the training sets that pose ethical issues – like in this experiment conducted by Stanford researchers who tested ChatGPT’s responses to sentences about Muslims.
This lack of explainability makes it difficult to comply with the requirements for equality and impartiality that many large organizations and public administrations are subject to. No bank can risk refusing a loan based on the applicant’s skin type, just like no corporation wants to be accused of discrimination in their hiring policy.
Security & privacy
Imagine this: the junior assistant helping you with your tasks shares confidential meeting notes or some proprietary source code with the rest of the world. That’s essentially what happened to Samsung, when employees entered sensitive content into ChatGPT’s AI Writer without realizing that OpenAI not only retains user input data, but can make it accessible to others too. Queries, answers, IP addresses and locations are stored by OpenAI on US-based servers and might be shared with affiliates – this is what you agree to when signing up for ChatGPT or another OpenAI model.
Whether you completely ban ChatGPT from your employees’ computers, like JPMorgan Chase, or, like Zurich, forbid them to feed customers’ personal information into the tool, it is essential to ensure that appropriate safeguards are in place to prevent confidential company data from landing in the wrong hands.
Sustainability
Complex AI models that require huge datasets and massive computing power aren’t just an issue for your company’s finances and resources. They pose an issue to the environment as well.
LLMs in general, and GPT in particular, require extortionate amounts of energy to train, fine-tune and run. They have also a significant water footprint: a study reports that Microsoft used about 700,000 litres of freshwater during GPT-3 training in its data centres – a comparable amount to what is needed to produce 370 BMW cars. A single conversation with ChatGPT consumes the equivalent of a 500ml bottle of water – imagine the total water footprint considering its billion of users!
What are the alternatives to ChatGPT and LLMs?
Semantic Folding is an alternative method for Natural Language Processing which addresses the shortcomings of LLMs in terms of reliability, transparency, security and sustainability. This machine learning approach leverages neuroscience to process text similar to our brains, and requires significantly less training data and computing resources than LLMs to achieve similar levels of accuracy.
Unlike LLMs which have been developed in a research context, Semantic Folding has been designed to solve AI use cases in a business context, especially extraction, classification, search, and comparison tasks. It is fully transparent, enabling deep inspection of parameters, and providing full explainability of models. From a privacy perspective, Semantic Folding is GDPR-compliant: no company data is shared or used outside of your organization.
The future of enterprise AI is promising
There is no stopping the meteoric rise of ChatGPT, LLMs and generative AI. Gartner estimates that, by 2025, 30% of outbound marketing messages from large organizations will be synthetically generated, and that, by 2030, 90% of any blockbuster film will be generated by AI. But before setting foot in these bleeding-edge technologies, it’s important to remember the risks they bear. It makes a huge difference whether you are a mom-and-pop pizzeria implementing ChatGPT to create a website, or a Fortune 1000 company having to fulfill ESG requirements. From an enterprise standpoint, certain standards in terms of reliability, transparency, security and sustainability need to be upheld, and companies looking to adopt AI solutions need to carefully evaluate the benefits and limitations of the technology they work with.
